 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Document Image Quality Assessment: A Text Line Based Framework and A Synthetic Text Line Image Dataset
Jun 05, 2019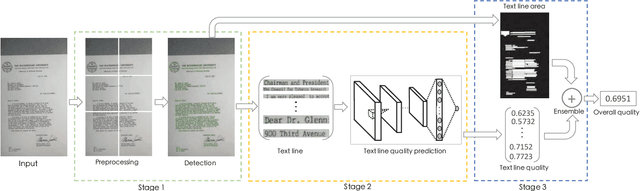
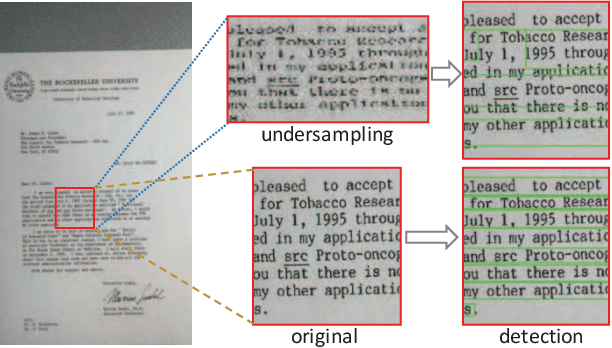
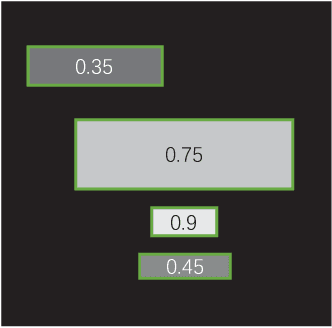

Since the low quality of document images will greatly undermine the chances of success in automatic text recognition and analysis, it is necessary to assess the quality of document images uploaded in online business process, so as to reject those images of low quality. In this paper, we attempt to achieve document image quality assessment and our contributions are twofold. Firstly, since document image quality assessment is more interested in text, we propose a text line based framework to estimate document image quality, which is composed of three stages: text line detection, text line quality prediction, and overall quality assessment. Text line detection aims to find potential text lines with a detector. In the text line quality prediction stage, the quality score is computed for each text line with a CNN-based prediction model. The overall quality of document images is finally assessed with the ensemble of all text line quality. Secondly, to train the prediction model, a large-scale dataset, comprising 52,094 text line images, is synthesized with diverse attributes. For each text line image, a quality label is computed with a piece-wise function. To demonstrate the effectiveness of the proposed framework, comprehensive experiments are evaluated on two popular document image quality assessment benchmarks. Our framework significantly outperforms the state-of-the-art methods by large margins on the large and complicated dataset.
CG-DIQA: No-reference Document Image Quality Assessment Based on Character Gradient
Jul 11, 2018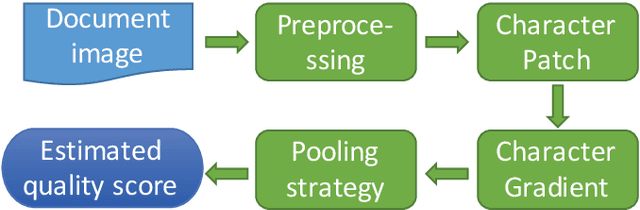


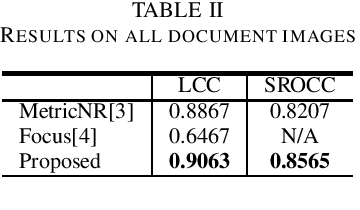
Document image quality assessment (DIQA) is an important and challenging problem in real applications. In order to predict the quality scores of document images, this paper proposes a novel no-reference DIQA method based on character gradient, where the OCR accuracy is used as a ground-truth quality metric. Character gradient is computed on character patches detected with the maximally stable extremal regions (MSER) based method. Character patches are essentially significant to character recognition and therefore suitable for use in estimating document image quality. Experiments on a benchmark dataset show that the proposed method outperforms the state-of-the-art methods in estimating the quality score of document images.